gathering urls for bilibili stream replays [part 3 - using data]
now that the data is in a consolidated file, a script is produced to get a random stream URL from the file and play it in a web browser
i did a practice code exercise years ago to pop a random item from a list, so i just copied it from the exercise page (here)
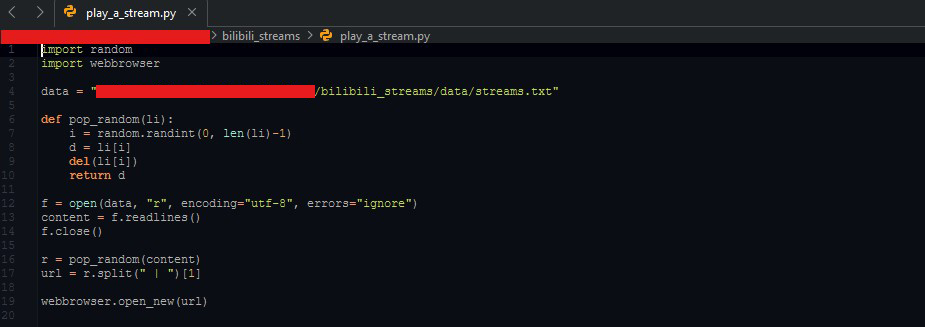
notes
using macros to gather data from a webpage can be very useful especially when combined with tools to refine the data for practical applications
i actually repurposed the script to aggregate other data including the usernames and associated URLs for uploaders i follow on both Pixiv and Bilibili
for Pixiv, i have followed more than 2,000 users over the past twelve years, and with the macro and scripts, i was able to compile all the information in less than three minutes
for Bilibili, i can find plenty of archived stream content to view or play in the background if there are no active livestreams at the moment
throughout the process of gathering data, there were no rate-limited requests or throttled API calls experienced; i essentially just used a few keystrokes to get URLs from each paginated webpage.