gathering urls for bilibili stream replays [part 2 - compiling data]
from the previous step, we now have lots of URL data aggregated; i move them to a separate folder to prepare for consolidation
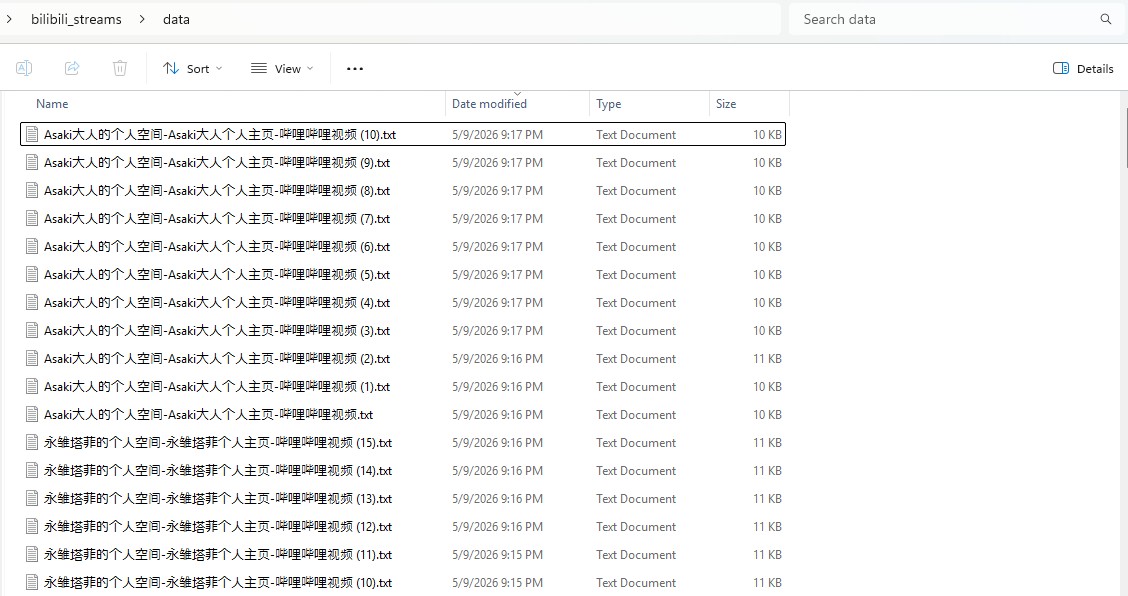
on examining one of the URL data files, we can see that there are URLs that don't reference video streams such as the ones on at the start of the file, so we can look to filter them out.
the lines that contain ( 直播回放 ) have the URLs that we want to keep, so we will look to consolidate these lines
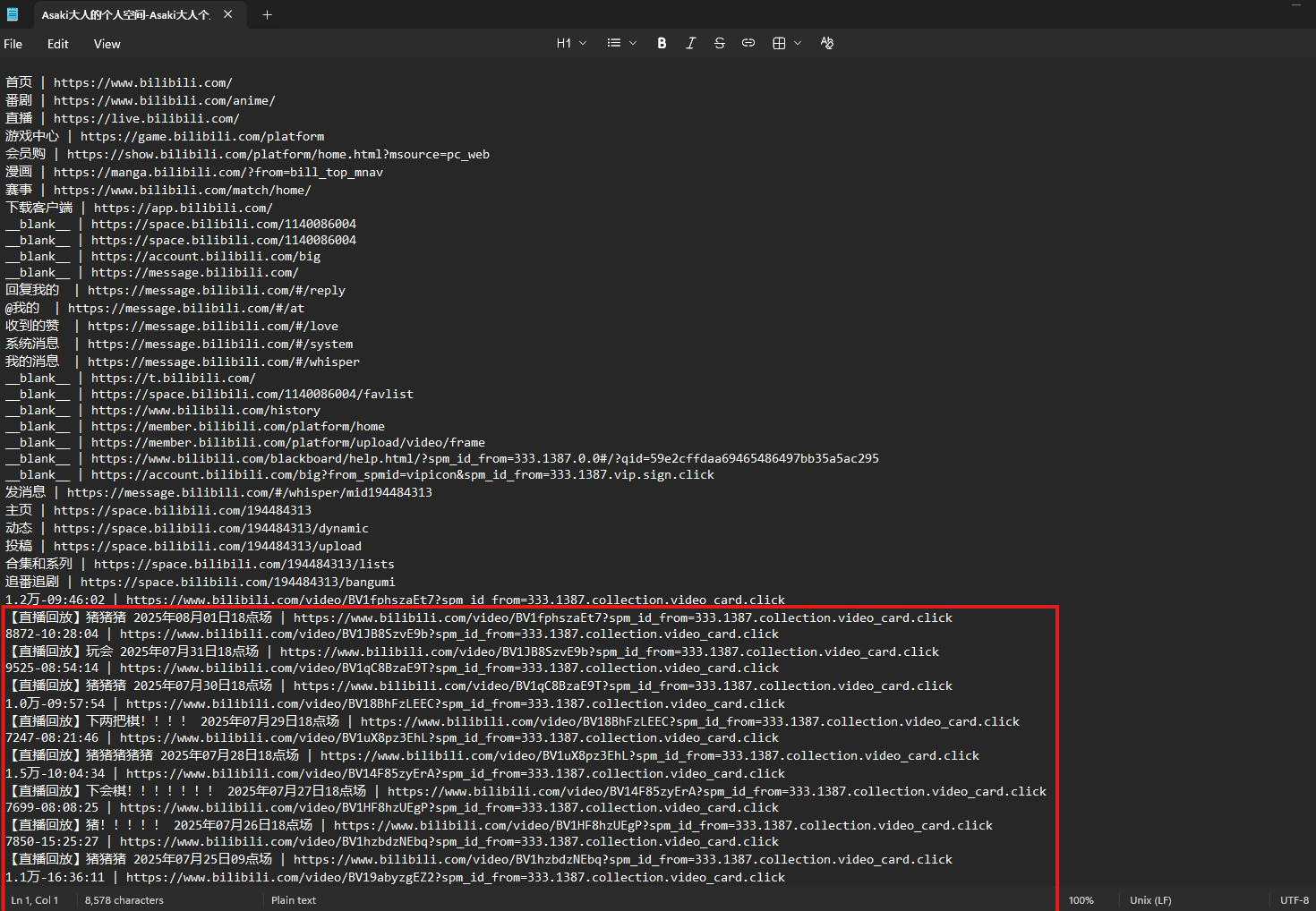
a python script is used to parse the files into one aggregate data file. each of the datafiles in the specified directory are read and the content is stored in a list object. i include logic to keep the lines containing ( 直播回放 )
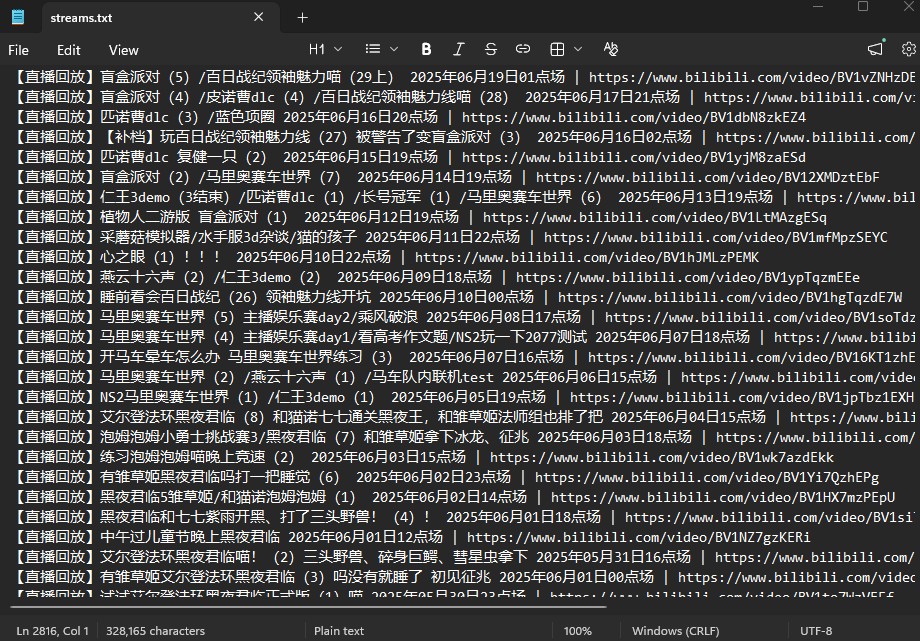
with the desired data in the list, i write the list contents to a new file which i named "streams.txt"
the file is successfully created after running the script and it looks like it has data; let's inspect the file
nice, the file has the URL display text and the URL itself for Bilibili stream URLs
now it should be easy to parse the URLs and select a random one to play in a web browser
 click here for Part 3
click here for Part 3click here for a code sample of the script